
Written by:
Brian Morin & Diana Stelmack
In this article we will walk through how Drifter uses AWS to capture gameplay telemetry to drive game design and business decisions for a small game studio.
This data is used for daily reports and ad-hoc exploration of the data via our Data Warehouse (Redshift Serverless.) Real-time processing is not a requirement as we generally use CloudWatch metrics for real-time metrics and decision making.
Source Data
Game data is logged by the game server as json events tagged via the “event” field. One json object per event.
Example Source Data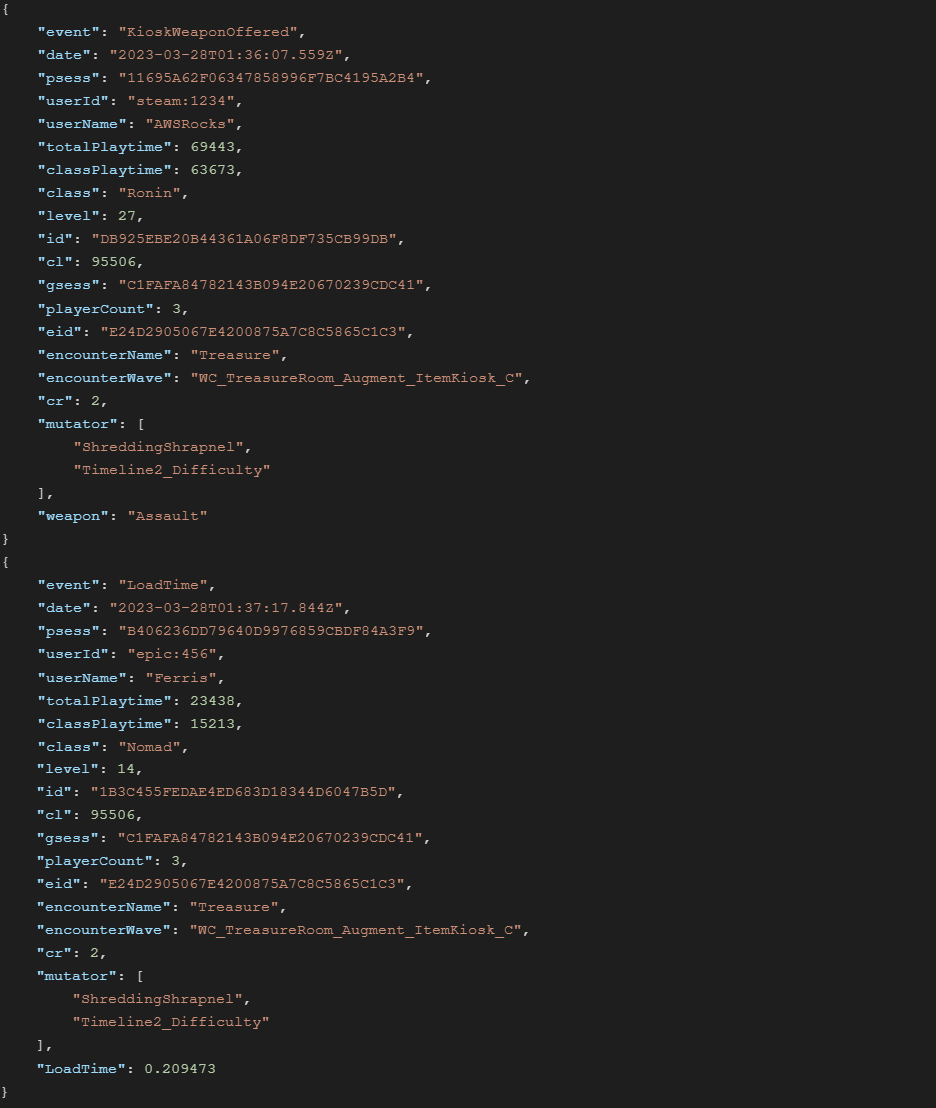
The source data is mostly schema free, however common columns usually retain the same name across events. The set of fields logged is denormalized outside of a few extremely common events (such as DamageDealt and DamageTaken 1), where we omit fields that can be looked up via other events after ingestion to keep the volume of source data down. Otherwise we favor logging everything to enable adoption of a wide range of tools (such as Athena and OpenSearch.)
Data Pipeline Architecture
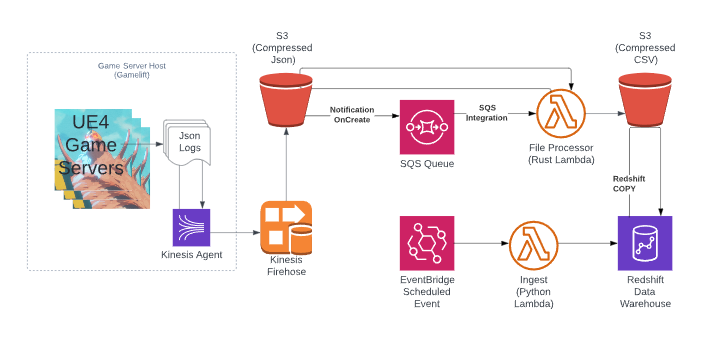
Source Data Capture
After game data is logged to disk, it is collected by a Kinesis Agent on the Game Server. Kinesis Agent then sends it to Kinesis Firehose where the data is compressed and written to S3 with at-least-once delivery.
Source data captured to disk with widely adopted code and minimal configuration involved is great for minimizing the risk of data loss and decoupling our logging format from the rest of the data pipeline. An earlier version of this system used a Kinesis Data Stream with Lambda integration to do bulk inserts into a SQL database. Bugs in the ingestion code resulted in data loss and the coupling of initial capture to the reporting schema complicated growing the schema (in addition to the scaling constraints of a SQL singleton.) Getting source data to disk quickly has been important.
File Processor Lambda in Rust
From S3 to SQS to Lambda
After source data is written to an S3 object, we use an S3 integration to post an ObjectCreated event to an SQS queue. From there we use an SQS Lambda integration to ETL the data from source json to schematized, validated and transformed csv. SQS is used to ensure objects are processed at least once (or added to a dead letter queue.) We can also configure how aggressively to batch multiple S3 objects into a single Lambda invoke for efficiency. Finally, it allows us to invoke multiple Lambda ETL instances within a configurable maximum concurrency limit (this happens when we run the Replay Tool which we will cover later.)
Rust was chosen for its low resource utilization, strong compile-time checks and fitness of the serde library.
Serde Enum and Structs
The event enum captures known events into their schematized version. Unrecognized event tags are mapped to Unknown, so they can be safely skipped and counted.
Event Enum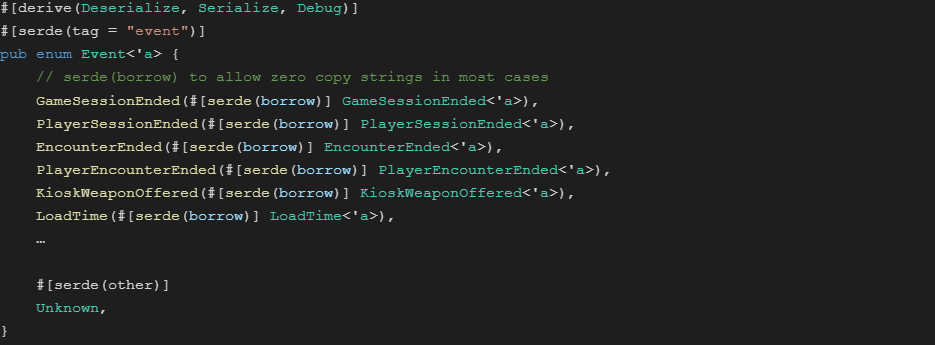
Example Event Struct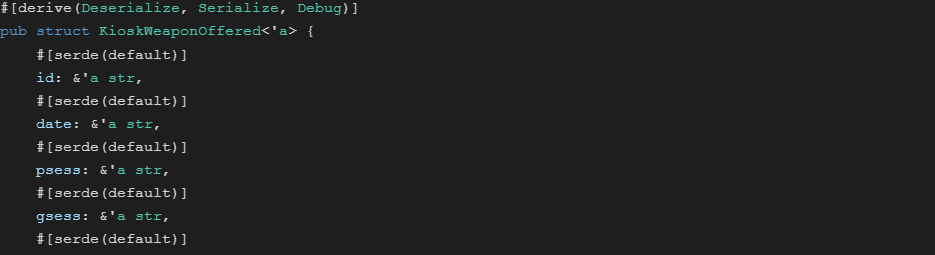
Validity, Uniqueness Checks and Transforms
After data has been deserialized into a struct, we then do validity checks, a uniqueness pass and do any transformations needed to match the schema in our data warehouse.
Validity checks include checking datetimes and uuids against regular expressions and making sure negative numbers aren’t in places that don’t make sense. Catching these early makes problems easier to track down due to having all of the context and prevents ingestion failures with a larger blast radius further down the pipeline.
Additionally, we do a uniqueness check to reduce the cost of processing data further down the pipeline. We regularly see batches where over a third of the events are duplicates. All of our events have a unique key, usually with a single uuid column, some via a compound key of 2 uuids. We feed these all into a HashSet and filter out duplicates as we go. This HashSet is the only state needed for processing outside of the scope of an individual event.
Finally, an optional transformation is done. Usually for fields like arrays and json fragments. However, any mismatch between the source data and reporting schema can be addressed via a custom transform as a last resort.
Example Validity Check and Unique Key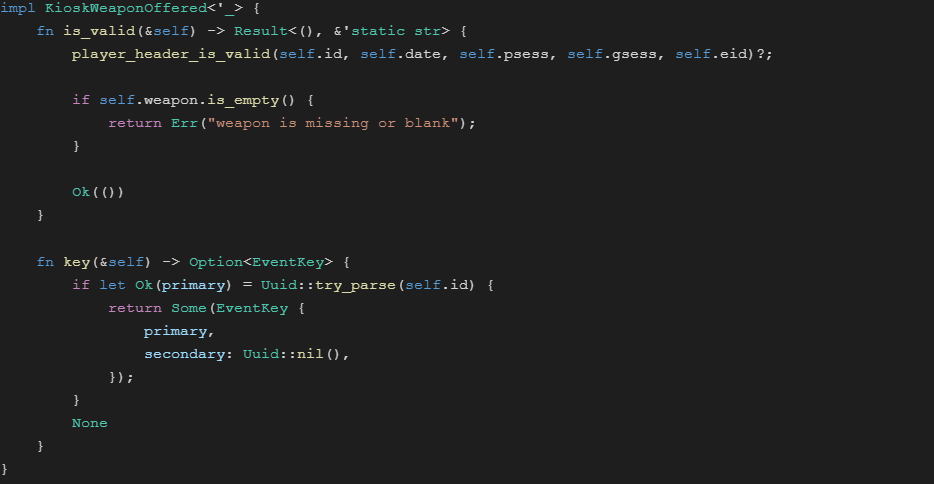
Deserialization Fingerprint and Writing Back to S3
After processing, we flush all of the processed data back to S3 as compressed CSV files by table with an object name of format:
{table_name}/{fingerprint}-{uuid}.csv
Example:
kiosk_weapon_offered/212c16e6ac9b7836-00087861f9dc4bc2807d0d13a7003814.csv
The fingerprint is a checksum of the column names in the output CSV so we can avoid reading the object contents when constructing ingestion commands for Redshift (we will go into detail on this later.) We calculate the fingerprint with a special serializer with mostly null implementations except struct name checksum. Crates like serde-reflection 2 will not work because they use the field names from deserialization instead of serialization.
Example Code for a Serialization Fingerprint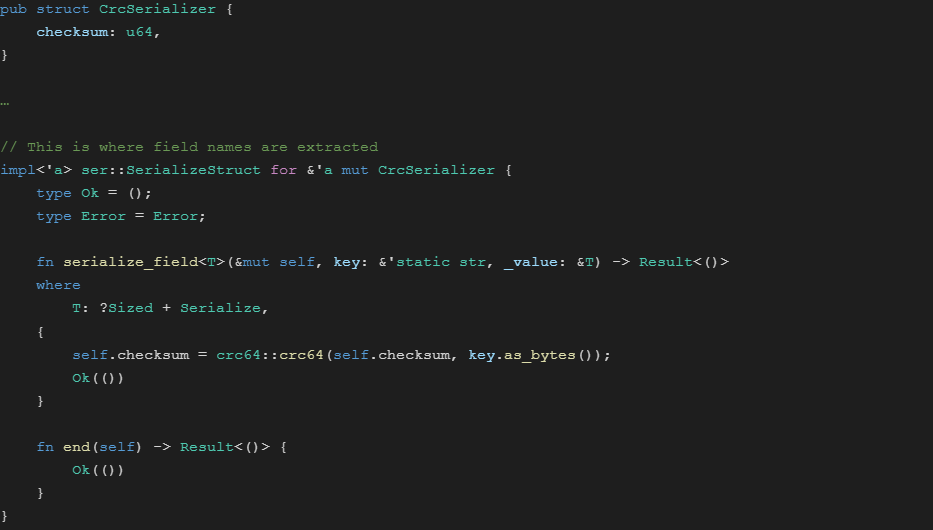
Ingestion into Redshift Serverless
Now we have a collection of compressed CSV files in S3 for each destination table, we need to get that data into our Data Warehouse. To do this we have a regularly scheduled job 3 in Event Bridge. Each invocation of this ingestion lambda inputs a series of table names so multiple tables can be ingested in parallel. The lambda collects the list of current .csv files for each target table and fingerprint pair. Since the COPY command needs a column list, we use the fingerprint to avoid having to poke into every object to get the header row. There is a cached list of header rows by fingerprint, but if we fail to find one, we will read the first few bytes of the first file to extract the header row so we can construct the COPY command. Then a manifest file is constructed, written to S3 and we run the COPY against a staging table in Redshift. After the copy is complete, we merge the staging table into the reporting table and ingestion is complete.
Example COPY Command
COPY staging.kiosk_weapon_offered(id, date,psess,gsess,eid,weapon) FROM 's3://yourbucket/kiosk_weapon_offered/something.manifest'
IAM_ROLE 'arn:aws:iam::1234:role/Ingest_Role' EMPTYASNULL MANIFEST IGNOREHEADER 1 REGION 'us-west-2' CSV GZIP TIMEFORMAT 'auto';
Because Redshift requires ownership of the table to truncate, our staging tables are created by the ingestion lambda via CREATE TABLE LIKE and need to be deleted or altered if we make a schema change to the reporting table.
Once the data is in our Data Warehouse, we then can run reports and ad-hoc queries against it.
Data Replay Tool
So far we have addressed ETL on source data as it comes in. Occasionally there is a need to reprocess data in response to a code defect or to make changes to the reporting schema. For example, to add support for a new field after it first appears in the source data stream. For these cases and to facilitate faster development iteration we have a simple data replay tool.
The Data Replay Tool is a Python lambda function that inputs a time window and then resends SQS events as they would appear from the S3 integration into SQS. Additionally, these events can be decorated with a comma separated list of table names to limit reprocessing to a subset of tables.
In the File Processor, we use a slight variant of the S3Event struct to capture this additional field.
Decorated S3Event in Rust
Comparison to AWS Glue
Prior to the system described, we were using AWS Glue to accomplish the same ETL. Difficulty root-causing ingestion errors, high wall time processing daily playtest data and lack of in-house Apache Spark expertise led us to explore an alternative using components we were familiar with from our experience building game services. Despite cost reduction not being the primary motive, about a third of our AWS bill from data processing was replaced by lambda functions running within the free tier. We suspect this is because there are not any joins or aggregation in our ETL outside of the uniqueness filter. Data frames via Glue may not be the best fit for the specific use case of spitting a single sparse rowset into dozens of tightly schematized rowsets.
Future Work
The current system is running well enough that we’re not currently pursuing further optimization, but a few directions to consider are:
- Investigate if Arvo or Parque instead of CSV speeds up the COPY into staging tables. CSV was selected to simplify debugging during development. This could also clear up ambiguity between null and empty string in the final phase of ingestion.
- Redshift has a new auto-COPY feature in preview https://aws.amazon.com/about-aws/whats-new/2022/11/amazon-redshift-supports-auto-copy-amazon-s3/
- Investigate using a Step Function to orchestrate commands into Redshift during the final ingestion step to avoid polling from Lambda.
- Lots of potential to further optimize the File Processor including simd-json, reading files in parallel and reducing memory allocations.
1 Additionally we only log detailed combat events for a sample of our live game play sessions and all of our internal playtests. Sessions with detailed logging are tagged via a field in the Begin and End Session events.
2 https://crates.io/crates/serde-reflection, https://github.com/serde-rs/serde/issues/1110, etc. will give you the wrong fingerprint for structs with renames or fields omitted on serialization.
3 Currently this is run every 6 hours on Production data and daily on Playtest data.